Advantages of Local AI Models
Recognized inherent benefits of deploying large language models on-site include the protection of privacy, high-performance capabilities, reliability enhancement, and an increase in return on investment. Locating the model on-device ensures the security of personal information and that prompts and responses are not shared with other services, which is necessary to observe privacy laws. Also, the service protection model enables reducing the interval for re-fulfilling new customer requests making it comfortable for watches.
There are also more options available regarding which hardware resource delivery based on performance can be constructed. These options include would and should include, CPU threading, temperature control, and, context length.
Another advantage of the on-premise deployment of LLM is its stability which is very important for research. Unlike models that are available from clouds and tend to be updated very frequently, local LLMs do not change quite often and therefore scientists can respectably hope to get constant results within the research scope, e.g. with extremely engaging models such as Llama or ProtGPT2 in designing proteins.
Moreover, local deployment avoids the costs of accessing cloud-based APIs, and service charges quite common for subscriptions of similar functionality make these models more inexpensive when they are used continuously or heavily. While some applications may benefit from using the cloud, such as GitHub Copilot, for example, cloud-based user-friendliness to provide coding assistance, Local LLMs are quite useful, possess internal confidentiality, and are economical for an array of applications and uses.

Figure 1: Local AI Models Cheat Sheet
Some tools for running Local AI Models
Developing LLMs in a local environment offers numerous benefits concerning data protection, adaptability, and cost savings, particularly for individuals who would rather not save anything in the cloud or any other remote services. For this reason, here are some ideas which concern methods that can be used to run local LLM:
Llama 3 and SeamlessM4T by Meta: These models allow for all data to be contained within a single device without any external access, which is very useful for data that is very private.
Jan: It is a very simple-to-use application that makes possible the use of more than 30 LLMs and maintains all this data locally. It also comes with a nifty text box and even a warning system to the effect that the model might be too demanding for the operating system.
Nvidia’s Chat with RTX: Accessible to graphic designers in a computer ‘lower powered configuration, uses Nividia RTX 30 Series Graphics for creating Q&A type problems with models like Mistral and Llama 2. This even includes the option of browsing towards local files as well as grabbing portable and opening it, and in addition on the resulted web browser on such a task based windows.
LM Studio: Developed in GUI format for Llama 3.1 and Phi 3 or any other LLM model for instance, this is a popular tool mainly because it carries a user-friendly interface and guides the user on how to set up and test the model.
Ollama: Has a nice and clean command line interface and comes with highly configurable and portable models such as Llama and Vicuña that are definitely the right fit for system administrators or other users who are experienced with command line.
GPT4ALL: In case of application is installed locally and works locally on processors for document handling, and at the same time there is a need to utilize OpenAI API including connecting to the internet capabilities.
Llamafile: Focuses on the development of portable Local Language Model applications cross platform for easy deployment.
Challenges with Local LLMs
Despite the advantages that the local processing of large language models (LLMs) has, the infrastructure overheads, maintenance, and scalability present a challenge. With future improvements brought about by edge computing and model compression, enhancement in the affordability and efficiency of local LLMs is anticipated. Lately developed large language models such as Google BERT and Open AI GPT-3 are advanced in responding accurately and appropriately but tend to be less effective when used on a classic and outdated database. Local LLMs also suffer from the need to be added to more recent or proprietary information to enhance reasoning about certain or new information, which is an essential aspect when developing any reliable and context-sensitive AI solutions.
- Information Outdated: When asked for current information—like revenue-wise the biggest companies—the information provided was already dated, as the model‘s training data comprised information limited only up to the year 2022. It was practically impossible to find any credible current statistics.
- Code Generation Compatibility Issues: A request to generate code, for example for Playwright scripts, resulted in code that in some cases was out of date, because the model was not aware of current developments, and therefore was unable to provide code for the recent versions of the software which was requested.
- Incorrect Information Related to an Ongoing Event: Questions about current affairs for instance, who is the winner of the India edition of the reality show ‘Big Boss’, produced false outputs. An example of such misinformation would, according to the model, refer to the winner of the year 2020 instead of 2024 due to the limitations in the training period of the model.
The solution for challenges of local LLMs
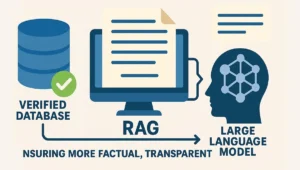
Retrieval Augmented Generation, RAG in short, is an enhancement to Local LLM by the inclusion of an information retrieval system to bring in relevant and current information from other sources such as documents or databases to support the response. This overcomes the problem associated with the knowledge of the model being out of date or missing the current information by providing in-the-moment data.
The Importance and Uses of RAG in Brief:
- Enhanced Output Reliability: RAG enhances the quality of information gathered while at the same time minimizing the fallacies in the information expounded making it fit for purpose where answers to questions are required as well as scenarios on facts-based presentations.
- Better Contextualization: It is More pleasurable to encourage the model to answer a given query in moderation with the more specific achievable goals presented in the task. Thus more coherent and on-point answers are availed which is crucial in activities like presenting records as well as condensing written narratives.
- Provides an Opportunity for Carrying out Difficulty Heightened LLM supported Processes: This makes RAG-coupled LMMs appropriate for use in complex layers of processes encompassing lots of information such as providing services to customers and producing various kinds of reports.
- Real-Time Updates: The aspect of being able to obtain and incorporate up-to-date information equips RAG with the ability to keep up with the changes in trends within topics thus, this is effective in areas that need freshness in content such as journalism, financial services, or healthcare.
Local LLMs: The Future of AI on Your Device
Local Large Language Models (LLMs) are changing the way we use AI. Instead of relying on the cloud, these models can run directly on your device, offering some big advantages like better privacy, lower costs, and more control over your data. Models like Llama 3 and Nvidia’s are already making AI more accessible and efficient. But there are still challenges, like keeping these models updated and managing the tech behind them. Tools like Retrieval Augmented Generation (RAG) help by fetching fresh information when needed. As concerns around privacy grow, Local LLMs will become even more important in how we use AI every day.
Conclusion
To summarize, constructing and running a local large language model gives developers the ability to use AI while protecting sensitive information, increasing efficiency, and allowing adjustments to be made to their products. Local models will be critical in turning responsive applications into personalized facilities as Explainable AI technology develops, but without compromising innovation or user privacy and requirements. Last but not least, local processing allows for reduced delays and enhanced security of users’ information while also promoting change in a constructive and accessible way to all in a world that is constantly getting smarter.
References
- Amazon Web Services, “What is a Foundation Model?” Retrieved 2024-11-14, from https://aws.amazon.com/what-is/foundation-models
- ProjectPro, “Foundational Models vs. Large Language Models: The AI Titans.” Retrieved 2024-11-16, from https://www.projectpro.io/article/foundational-models-vs-large-language-models/893
- Deepchecks, “Model Parameters.” Retrieved 2024-11-14, from https://deepchecks.com/glossary/model-parameters
- Grootendorst, M. (2024, July 22). “A Visual Guide to Quantization.” Retrieved 2024-11-16, from https://www.maartengrootendorst.com/blog/quantization
- Gimmi, P. (2023, September 8). “What is GGUF and GGML?” Retrieved 2024-11-16, from https://medium.com/@phillipgimmi/what-is-gguf-and-ggml-e364834d241c
- Rohit (2024, October 8). “The 6 Best LLM Tools to Run Models Locally.” Retrieved 2024-11-16, from https://callmerohit.medium.com/the-6-best-llm-tools-to-run-models-locally-4d054141afad
- Taposthali, V. (2024, July 4). “Building a Local Large Language Model: Empowering Localized AI Development.” Retrieved 2024-11-16, from https://medium.com/@visheshtaposthali/building-a-local-large-language-model-empowering-localized-ai-development-8477a5d26a9a
- IBM Technology, “Running AI Models Locally.” Retrieved 2024-11-14, from https://www.youtube.com/watch?v=5sLYAQS9sWQ&t=2s&ab_channel=IBMTechnology